

苹果发布两款 AI 电脑!一款自砍 1000 元,一款能部署满血版 DeepSeek
苹果发布两款 AI 电脑!一款自砍 1000 元,一款能部署满血版 DeepSeek挤牙膏的新款 iPad Air 和 iPad 果然只是开胃小菜,今天苹果为我们带来了更有看点的 MacBook Air 和 Mac Studio 更新。
来自主题: AI资讯
8263 点击 2025-03-06 10:01
挤牙膏的新款 iPad Air 和 iPad 果然只是开胃小菜,今天苹果为我们带来了更有看点的 MacBook Air 和 Mac Studio 更新。

「某某公司租的机器狗,都累没电趴窝了。」
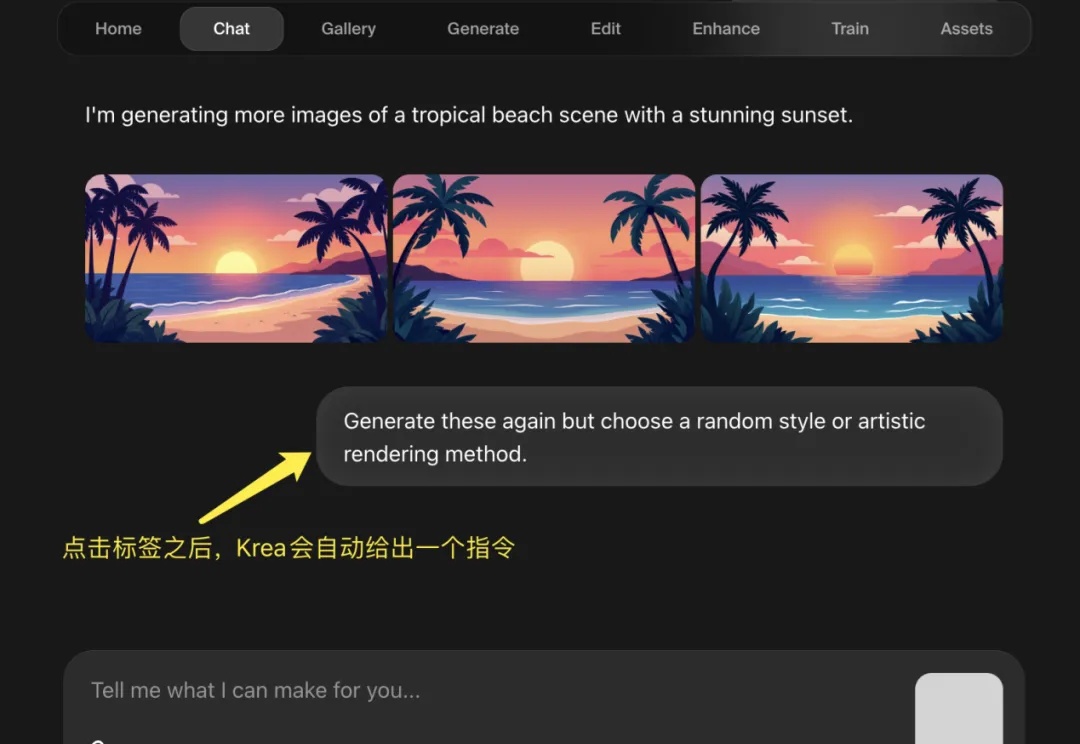
在 R1 推理模型大火之后,全民接力集成 DeepSeek,有硅基流动这样的大模型云服务平台、有腾讯元宝这样的 Chatbot,甚至微信这样的顶流。但是,AI 图片类产品却鲜少有接入 DeepSeek R1 的新闻,而从 DeepSeek-R1 发布到 Krea 宣布上线新功能仅仅 10 天,这个反应应该是图像产品中最快的。

随着 DeepSeek 问世,从春节至今,和AI有关的资讯与讨论已经让人有些疲劳。然而,相关讨论大都聚焦在产业、投资和技术方面,其中不乏优质信息,但仍缺少一个重要的视角——作为普通用户,我们如何看待并使用AI。
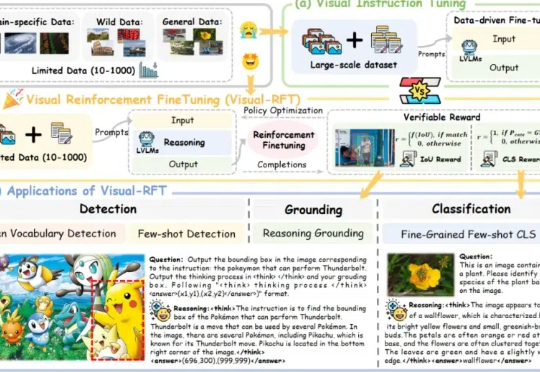
通过针对视觉的细分类、目标检测等任务设计对应的规则奖励,Visual-RFT 打破了 DeepSeek-R1 方法局限于文本、数学推理、代码等少数领域的认知,为视觉语言模型的训练开辟了全新路径!

在 DeepSeek 生成的文本中,有 74.2% 的文本在风格上与 OpenAI 模型具有惊人的相似性?这是一项新研究得出的结论。这项研究来自 Copyleaks—— 一个专注于检测文本中的抄袭和 AI 生成内容的平台。

3月3日,智谱公布了最新一轮融资:本轮战略融资金额超10亿元人民币,参与投资方包括杭州城投产业基金、上城资本等。智谱称:此次融资旨在推动智谱国产基座GLM大模型的技术创新和生态发展。
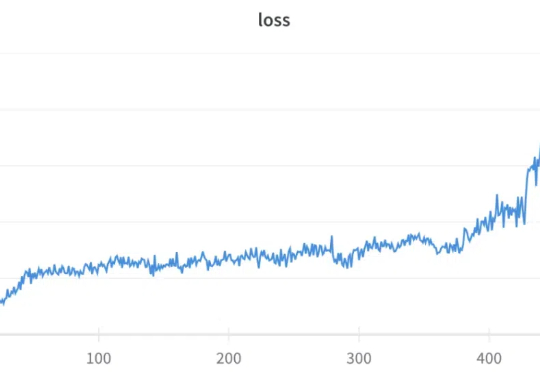
GRPO(Group Relative Policy Optimization)是 DeepSeek-R1 成功的基础技术之一,我们之前也多次报道过该技术,比如《DeepSeek 用的 GRPO 占用大量内存?有人给出了些破解方法》。

风险投资行业中,古典 VC 在科技创新浪潮中捕捉机会追求胜率,讲究品牌效应、二八原则和师徒传承。过去几年,VC 行业集体丧失贝塔,无法抓住阿尔法的 VC 已经被汰换,传统 VC 模式的弊端也逐渐暴露。VC 模式的换代迎来了 Deepseek 时刻。
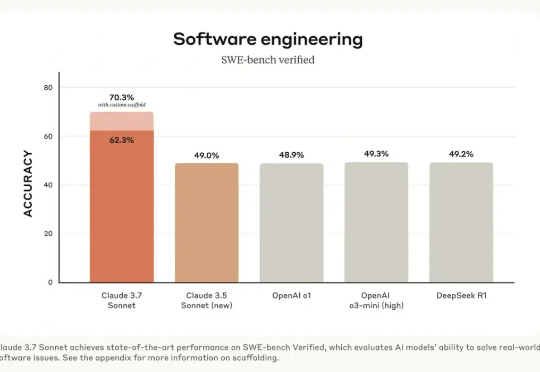
昨天,Claude 3.7 Sonnet 正式发布。根据目前的各项测评,这个模型可以说是全宇宙最好的代码生成模型,超越了 DeepSeek R1 和 OpenAI 的 o3 等模型。如果你是程序员,一定要第一时间切换过去,用下这款模型。